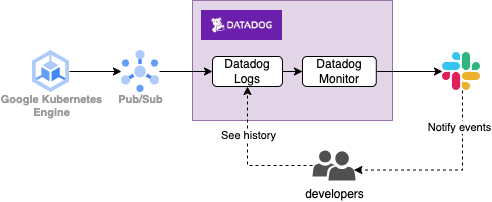
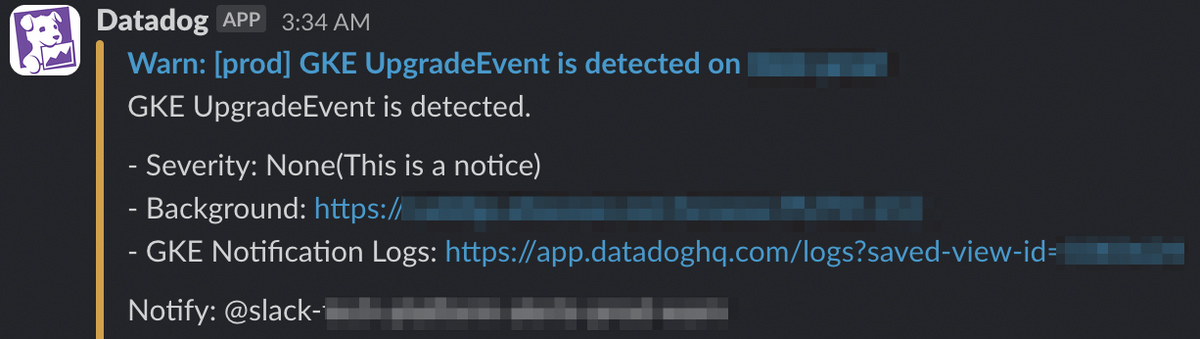
(2024-04-09追記)補足、訂正済みの記事がTech Blogで公開されました。
Software Design 2024年1月号で「Google Cloudを軸に実践するSREプラクティス」連載の最終回として、Cloudflareの基本と運用のポイントについて書かせていただきました。*1 読み返してみるとわかりづらい部分があったのでこのエントリで補足します。また、もし間違いがあったらこのエントリに訂正内容を追記します。
補足
p152: Developer Platform
運用上の課題としては、まだIAM(Identity and Access Management)に相当する機能がないため、サービス間の認可やユーザーアカウントごとの認可を細かく設定できません。
Developer Platformの文脈で、運用上の課題として上記のように書きました。 細かく設定できないという部分が抽象的すぎるため、具体例を補足して書き直してみました。
運用上の課題としては、まだIAM(Identity and Access Management)に相当する機能がないため、最小の権限でのワークロード実行制御ができません。 たとえば、「特定のCloudflare WorkersからはCloudflare R2の読み取りだけしかできない」といった制御です。 一方「特定のCloudflare Workersから特定のCloudflare R2のすべての操作」はBindingによる紐づけを前提としており、制御できるようになっています。 ユーザーアカウントに関しては、RBAC機能を利用してある程度権限が管理できますが、リリース環境ごとに権限を分離するなどの制御はできません。 とはいえ、IaCを前提としたGitリポジトリ側での統制により、ある程度担保できるでしょう。 また、管理コストは上がりますが、本番環境とその他の環境をアカウント(テナント)やドメイン単位で分離することも有効な手段です。
訂正
p146: Cloudflare DNS
(2023-12-20追記)
これを使うことがCDNをはじめとするCloudflareのEdge Serverによる最適化の恩恵を受けるため必須条件となります。 通常、CDNサービスを利用するときは、任意のDNSプロバイダで、DNS Recordの向き先をそのCDNのEdge ServerのIPやホスト名に変更します。しかし、Cloudflareの場合は、Cloudflare DNSを使ってDNS Recordを管理しなければなりません。
こちらのCloudflare DNSの説明ですが、私の勘違いで事実と異なっていました。 実際にはBusiness Plan以上であれば、任意のDNSプロバイダでCNAMEを指定してCloudflare Edge Serverへプロキシできます。 つまり、Cloudflare DNSはCloudflare CDNを使うための必須条件はでありません。 詳細は下記の公式資料を参照してください。